Moving to HTTPS?
Need to crawl-check the site for mixed content?
A previous post Impact of HTTPS Chrome warning on SEO: 2018 vs. 2014 sums up, or rather, refers to other articles discussing the importance of HTTPS. This is mildly interesting, since serving content over HTTPS has been a ranking factor since 2014, so you already know about it.
Chrome telling visitors they are on a "not secure" site beginning July 2018 - the key message of that post, may rise your eyebrows, because it a) discourages potential users / buyers / clients / ad-clickers and b) it has an impact on rankings through higher bounce rates.
But what about mixed content?
No HTTPS? Bad.
Unencrypted parts of an HTTPS page? Maybe worse.
Here is why:
Currently, Chrome users get information about encryption being in place (green padlock), or no explicit security info at all. Unless, you migrate to HTTPS, poorly:
If you serve insecure content on an encrypted page (mixed content) users get a warning next to the URL in address bar.
Sadly, the result is worse then if there was no attempt to use encryption at all. Would you mind browsing a news site with no encryption, but no warnings showing up? Probably not. Wouldn't you, being an ordinary user, give it at least a second of thought what it means that "parts of a page are not secure", and how could that be threat?
Mixed content - a problem now, getting bigger later
It is likely, that when the day comes, and Google Chrome will require HTTPS not label your site "Not secure", there will be no mercy with mixed content. Why? How much, or rather what kind of insecure content should be tolerated? And why even raise the question?
Surprisingly, as of today (2.7.2018), there were at least 4 sites with mixed content, or invalid certificates on the secured version within the first 150 world's most popular sites, that is, entries in the The Moz Top 500:
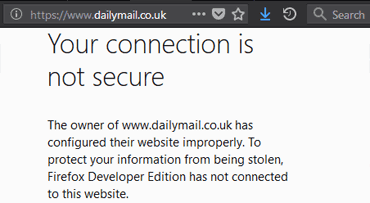
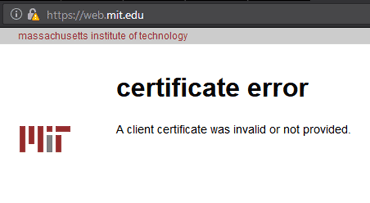
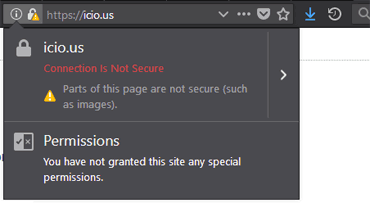
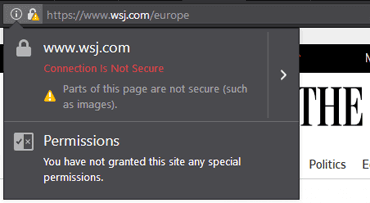
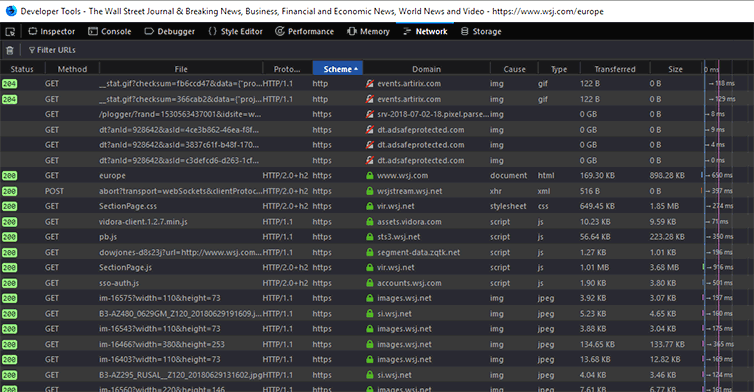
The fourth example of mixed content warning is on the european Wall Street Journal page. It makes 300 requests, as can be seen in Developer Tools of Firefox Developer Edition:
Solving this may not be easy, since the guys at WSJ likely have little control over a 3rd-party script which attempts to load them.
Anyway, this method of inspecting a site for mixed content - using developer tools, is one of the fourth proposed. Check them out:
Check your site for mixed content
Option #1:
Check inside the browser using developer tools
Pressing F12 in Chrome, Firefox, Edge, Explorer, or enabling developer tools in Safari will let you inside the browser's backstage.
Here, the respective browsers differ a little, but they all offer an Inspector for the code of the actual page and relevant resources, a Debugger, Console, Performance, Memory and Network tools. The last mentioned displays detailed live info on requests/responses the browser makes/gets when loading the page.
- Pro: All the details of a page load, as it happens. This means, even items being requested subsequently by scripts are being checked.
- Con: One page at a time only checked manually.
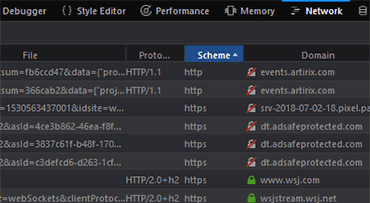
Mixed content requests inside the Network Tab
The complete browser-server exchange is displayed in the Network tab, ordered chronologically by default. Many details on all requests/responses are available, so this is also a great tool to evaluate possible performance drawbacks, e.g. wrong loading order of resources, CSSs, scripts. But in this case, we are after the green locks, or rather, items which miss them - the insecure ones.
Ordering by Scheme helps to get HTTP requests at the top. However, even HTTPS one can get a insecure (non-)response. Ordering by domain makes it easier to see insecure content grouped together, if request and responses don't match and non-secure responses come from several domains.
Blocked mixed content requests inside the Console
Also, check out the Console. Here you can find active mixed content, that has been ignored (mostly scripts and potantially hazardous items). To clearify, passive mixed content, such as images, still triggers warnings, but is seen potentially harmless and is being displayed inside the page.
Methods of eliminating them are dependent on their source. When a page is served over HTTPS, mixed content often comes from other sites for historical reasons, and can be solved easily by asking for the same items from a secure version of the source, that was meanwhile made available by the provider. Omitting the protocol in the link is good a solution, if HTTPS is the primary protocol of source.
Option #2:
Specialized online or downloadable apps or browser extensions
Tools created specifically for the purpose of mixed content discovery are available.
Depending on the tool of choice, the option to scan the whole site might be a way to go. The scan will probably not be as thorough as a browser check, since the tools do not process the whole page and its dependencies, but it actually might not be needed: Once you have fixed the pinpointed mixed content and the page/site is 100% secure. you konw the tool has done the job right. In the event there are non-secure item left, you can then resort to option one.
- Pro: Ease of use. Possibly the best option for smaller, not too complicated sites.
- Con: Not as reliable as the previous option.
| Name | Type | Price | More info |
|---|---|---|---|
| JitBit non-secure content check | Online / Installable | Free | Limited to 200 pages, results available for 10 minutes. |
| HTTPS Checker | Online / Desktop | Free / Paid | The free version for desktop is limited to 500 URLs and can be licensed for more pages and features. The online verison (Reporter) comes at a cost and allows real-time continuous monitoring. |
| Why No Padlock? | Online | Single page scan, detailed info on SSL certificate, results available online for 30 day on a unique url. | |
| Mixed Content Checker in WebSite Auditor | Online | Free / Paid | Part of a larger suite of tools - WebSite Auditor. The free version is missing out on automation and reporting features, limited to 500 URLs, but still fully usable for optimization of smaller sites. |
| Qualys SSL Server Test | Online | Free | Tool for a thorough test of encryption implementation. |
| Really Simple SSL | Wordpress plug-in | Multiple pricing options | Checks your theme and plugin files and database for references to CSS and JS libraries with HTTP links or resources that would be blocked over SSL. |
| HTTPS Mixed Content Locator | Chrome extension | Free | Lists HTTP elements on a page and even locates passive mixed content visually. |
Finally, some useful material on Tracking down mixed / insecure content by Really Simple SSL, and a video walk-through for the last mentioned Chrome extension by Pericror:
Option #3:
Use an SEO crawler / scraper / extractor
Crawlers (or scrapers, extractors, spiders) are used to automate repetitive steps when analysing or bulk-downloading data from a site. The action is similar to that which Googlebot or others bots perform. The output is very versatile and basically is a database of content, and dozens of parameters of the site. It is the best way to gain valuable insights into your indexability, hierarchy, structure, UX, onsite SEO parameters, performance, security, etc.
Many reports/views into your site are built-in and vary depending on the crawler of choice. Typically these are the frequency of keywords, meta tag statistics, info on use of canonicals, sitemaps, and also mixed content.
Advanced crawlers allow you to extract custom data from sites. For example, you can set it up to harvest a competitor's e-shop inventory, nicely by Product name | Price | URL | Availability | Rating | whatever..
But in case of mixed content, you want to...
Option #3.1:
Feed the Screaming Frog!
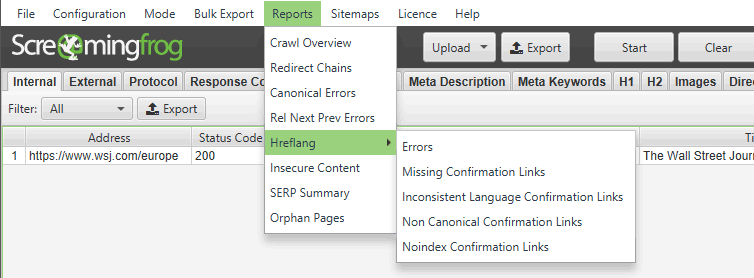
Screaming Frog is a popular SEO Spider Tool which does all the above and more. As of version 9.4., the following technical SEO reports are available, besides the obvious stats.
Insecure (mixed) content report is one of them. The output is an excel sheet.
Option #3.1.1:
Feed the Screaming Frog with regular expressions!
Great features of Screaming Frog are the Custom Search and Extraction.
They enable does/not contain searches, but more importantly regex, xpath and csspath extractions. The first means, you can really rake anything from the site's source, be it meta-data, scheme.org site structure, OpenGraph- or Twitter-specific tags, etc. And you can set them up to scan for mixed content too:
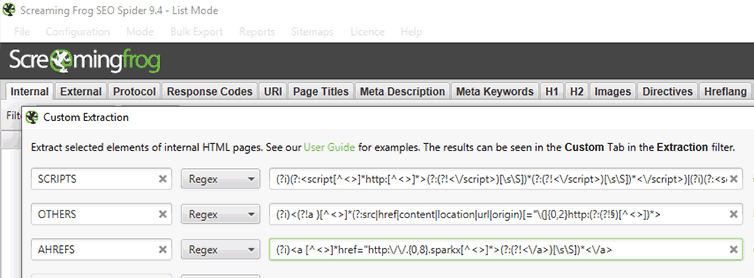
This follow-up post on mixed content regex extraction discusses scanning for these types of mixed content:
- a hrefs leading to http://* (elements get listed with content in between tags for easier identification in source code)
- scripts - external or internal, which do not follow document.location.protocol
- elements with values containinghttp://* inside src, href, data-href, content, url, srcset, location, movie and value, with the exception of XMLNS and DOCTYPE.
With the exception of complicated nested tags, this hopefully resolves the following mixed content:
- favicons and tiles
- meta-refresh
- canonicals
- inline JS redirects even with non-ahrefs
- flash
- audio, video tags
- RSS links
- Open Graph tags, FB widgets
- iframe src
- backgrounds a border images in inline css
Regular expressions for mixed content detection
These regular expressions for mixed content crawling are not limited to Screaming Frog, but can be used with any crawler which works with regex, so get them here.